openBHB dataset
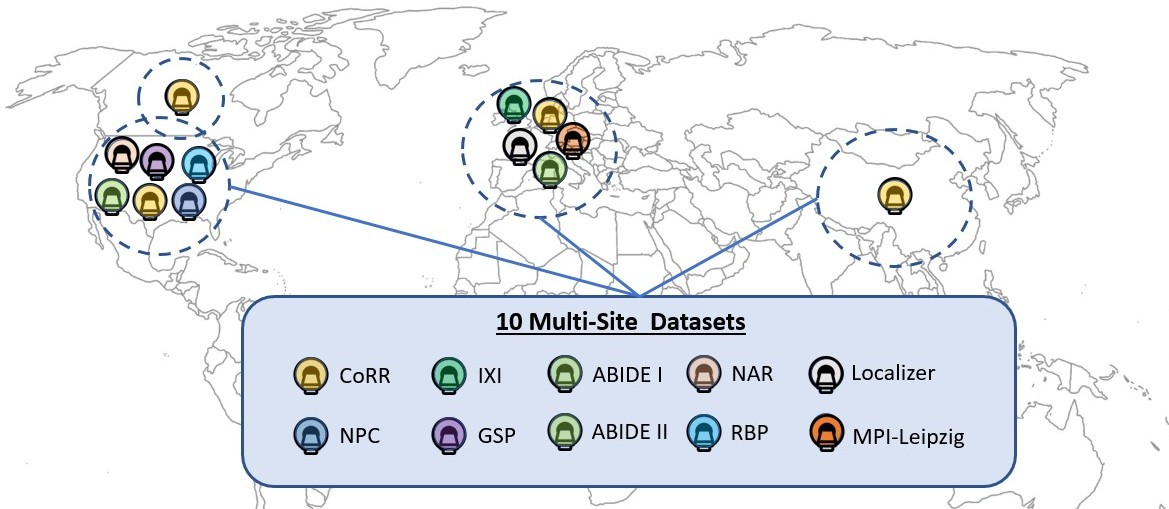
Contents
Healthy controls dataset
OpenBHB aggregates 10 publicly available datasets. Currently, openBHB is focused only on Healthy Controls (HC) since the main challenge consists in modeling the (normal) brain development by building a robust brain age predictor. As a result, we only included HC from ABIDE 1 and 2, and we left out the subjects with Autism Spectrum Disorders in the current release. OpenBHB contains $N=5330$ 3D T1 brain MRI scans from HC acquired on 71 different acquisition sites coming from European-American, European, and Asian individuals, promoting more diversity in openBHB. To manage redundant images, one session per participant has been retained along with its best-associated run, selected according to image quality. We also provide the participants phenotype as well as site and scanner information associated with each image, which essentially includes age, sex, acquisition site, diagnosis (in our case only HC), MRI scanner magnetic field, and MRI scanner settings identifier (a combination of multiple information composed of a subset of the repetition time, echo time, sequence name, flip angle, and acquisition coil). Some widespread confounds are also proposed, such as the Total Intracranial Volume (TIV), the CerebroSpinal Fluid Volume (CSFV), the Gray Matter Volume (GMV), and the White Matter Volume (WMV).
| Available | Source | # Subjects | # Scans | Age | Sex (\%M) | # Sites | # Settings | # Modalities (others available) |
|---|---|---|---|---|---|---|---|---|
| ✔️ | ABIDE 1 | 527 | 527 | 17 ± 7.7 | 82 | 20 | 1 | T1w (rfMRI) |
| ✔️ | ABIDE 2 | 555 | 555 | 14.9 ± 9.5 | 69.5 | 17 (1 out) | 1 | T1w (rfMRI) |
| ✔️ | CoRR | 1368 | 1368 | 25.9 ± 15.9 | 49.4 | 26 (8 out) | 1 | T1w (rfMRI) |
| ✔️ | GSP | 1570 | 1570 | 21.5 ± 2.9 | 42.4 | 5 | 1 | T1w (rfMRI) |
| ✔️ | IXI | 558 | 558 | 48.7 ± 16.4 | 44.4 | 1 | 3 | T1w (T2w, DWI, PD) |
| ✔️ | Localizer | 76 | 76 | 24.5 ± 6.6 | 42.7 | 2 | 1 | T1w (fMRI) |
| ✔️ | MPI-Leipzig | 282 | 282 | 35.6 ± 17.8 | 60.3 | 1 | 2 | T1w (rfMRI) |
| ✔️ | NAR | 289 | 289 | 22.1 ± 4.9 | 41.9 | 3 | 1 | T1w (T2w, fMRI) |
| ✔️ | NPC | 64 | 64 | 26 ± 4.2 | 55 | 1 | 1 | T1w (T2w, DWI, rfMRI) |
| ✔️ | RBP | 41 | 41 | 23.1 ± 5.0 | 48.8 | 1 | 1 | T1w (T2w, DWI, rfMRI) |
| Total | 5330 | 5330 | 25.3 ± 15.0 | 52.1 | 71 (9 out) | 13 | T1w |
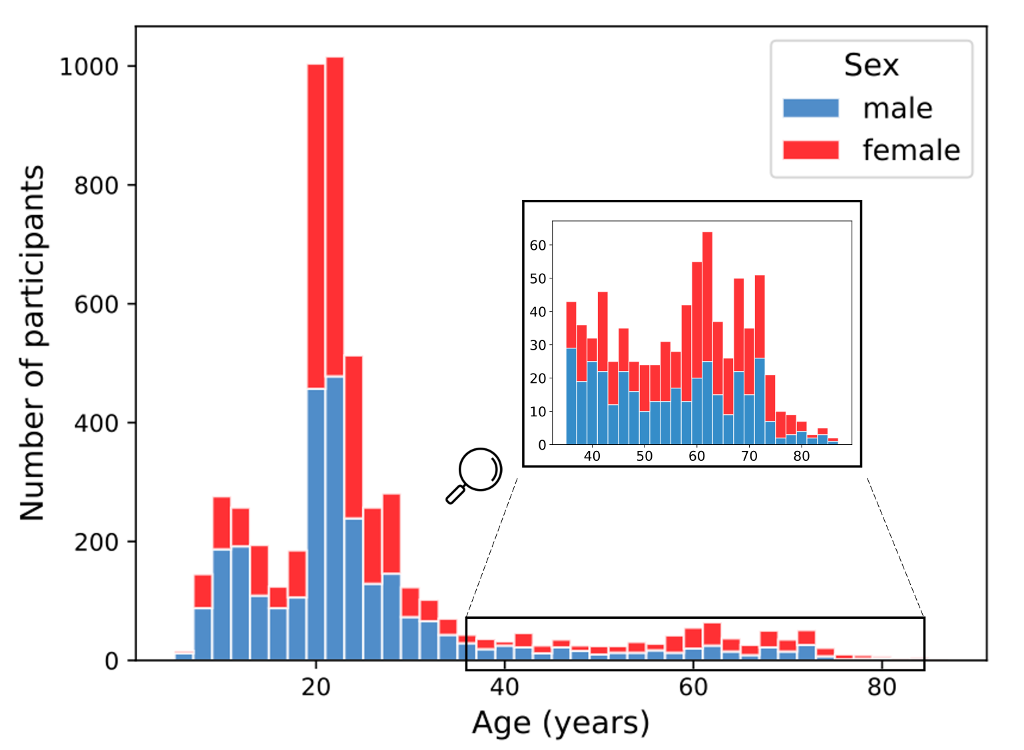
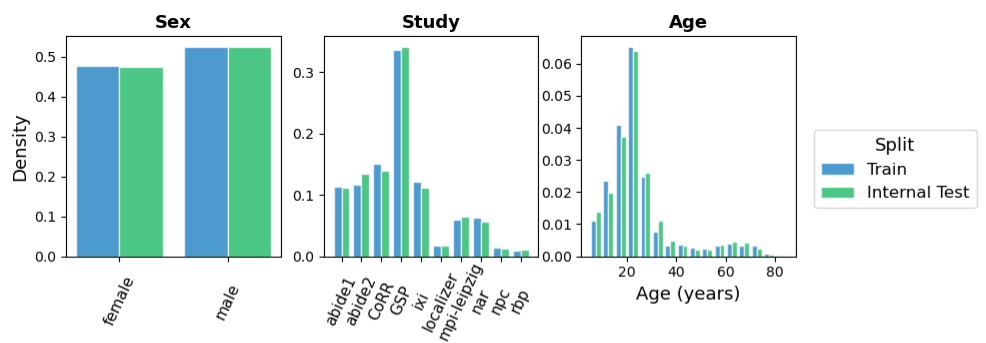
From the population statistics it should be notice that sex distribution is globally well balanced for all age bins. Age distribution contains 2 main modes centered around 10 years old and 25 years old with a long tail above 40 until 88 years (and fewer samples in this range).
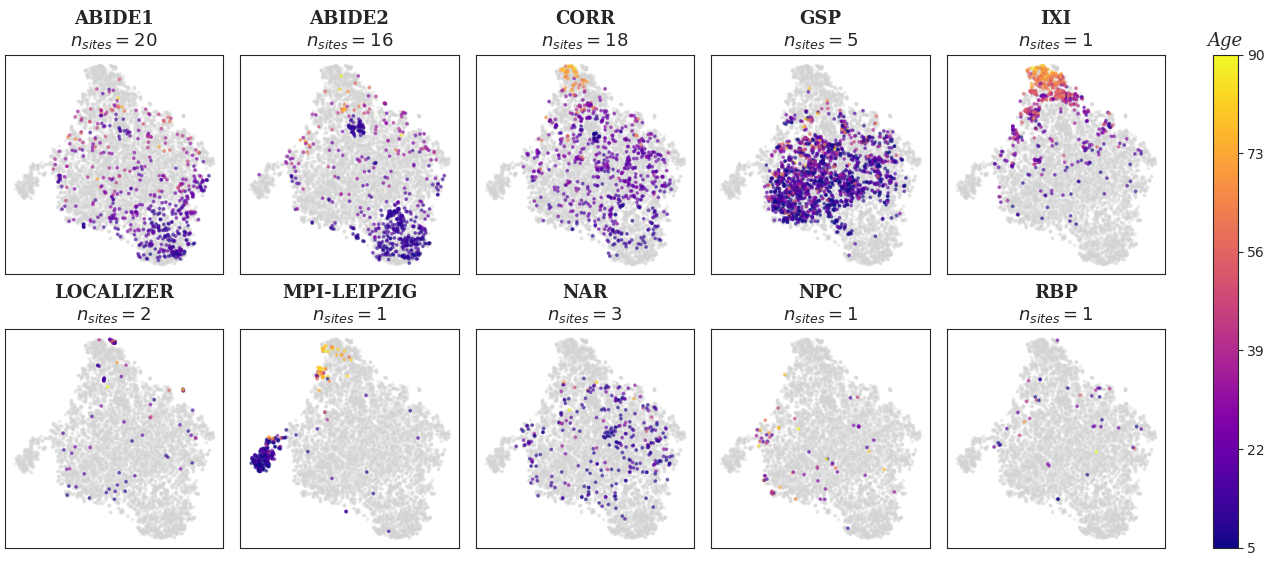
Additionally, we represented the t-SNE visualization of ROI extracted from VBM data per study. This plot clearly suggests that age and site effect are driving the representation, thus justifying the objective of openBHB challenge. Cohorts with both a large number of sites and a large age range cover wider regions in t-SNE space than others (e.g CoRR covers almost all regions while GSP and IXI cover only middle and upper regions; even if they are lifespan, they only include 6 sites together vs 18 sites for CoRR). This is even more obvious with MPI-Leipzig that covers mostly small left and upper regions while it is also lifespan.
Pre-processed datasets
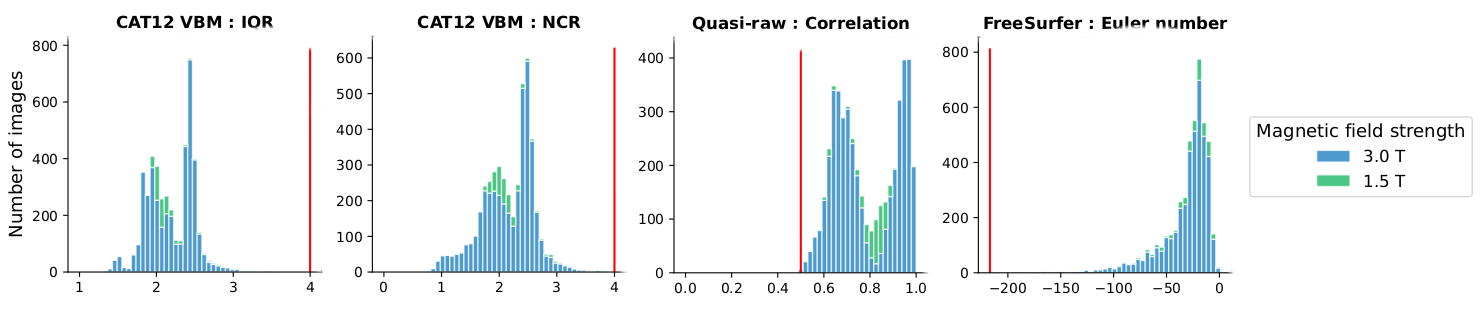
All data are preprocessed uniformly with the brainprep module using container technologies comprising Quasi-Raw, CAT12 VBM, and FreeSurfer, which enables controlling the different software versions over time. We conducted semi-automatic Quality Controls (QC) guided with quality metrics.
Quasi-Raw Minimally preprocessed data were generated using ANTs bias field correction, FSL FLIRT 9 degrees of freedom (no shearing) affine registration to the isotropic 1mm MNI template, and the application of the brain masks. The QC was driven by the average correlation (using Fisher’s z transform) between registered images retaining images at a threshold higher than 0.5.
Voxel-Based Morphometry (VBM) was performed with CAT12. The analysis stream includes non-linear spatial registration to the isotropic 1.5mm MNI template, Gray Matter (GM), White Matter (WM), and CerebroSpinal Fluid (CSF) tissues segmentation, bias correction of intensity non-uniformities, and segmentations modulation by scaling with the amount of volume changes due to spatial registration. VBM is most often applied to investigate the GM. The sensitivity of VBM in the WM is low, and usually, diffusion-weighted imaging is preferred for that purpose. For this reason, only the modulated GM images are shared. The QC was driven by the Noise Contrast Ratio (NCR) and Image Quality Rating (IQR) retaining images at a threshold below than 4.
FreeSurfer Cortical analysis was performed with FreeSurfer “recon-all”. The analysis stream includes intensity normalization, skull stripping, segmentation of GM (pial) and WM, hemispheric-based tessellations, topology corrections and inflation, and registration to the “fsaverage” template. From the available morphological measures, the Desikan and Destrieux ROI-based cortical thickness (CT), surface area (SA), and curvature (CR) are shared. The same vertex-wise features are accessible on the high-resolution “fsaverage” mesh (163842 nodes). The QC was driven by the Euler number retaining data at a threshold greater than -217.
Training/test split
Providing a test set that is representative of the training set for a particular task is essential in ML to avoid unexpected bias in the final predictions. In our context, openBHB contains several critical statistics that must be preserved between training and test, in particular participant’s age and sex as well as the acquisition site. Considering the large number of sites (>60) and age bins with a reasonable binarization scheme (e.g 5-years bins), it is prohibitive to use the naïve stratification approach based on the cartesian product between sites, binarized age and sex (there would be enough samples per bin). To properly define such a split, we used the iterative statification algorithm that tries to optimally preserve the different age, sex and site histograms between train and test. Using that method, we obtained a split that preserves well age, sex and site statistics.
In the context of the openBHB challenges, we also derived a private test set, named in the sequal privateBHB. PrivateBHB is fully independent from openBHB preserving age and sex statistics but containing images acquired on independent sites. These sites are kept private to avoid any bias during the challenge. privateBHB can be used to evaluate the generalization capacity of models on never-seen sites.
Finally, we complemented our analysis by visualizing VBM data for openBHB train set, both openBHB and privateBHB test sets with t-SNE (using only ROI for computational reasons). Most regions are covered by the training and test sets in the representation space but some regions are only covered by privateBHB test set (e.g bottom and right regions, usually for younger participants).
